🎯 Project Overview
An advanced R Shiny application that automatically classifies baseball pitch types from TrackMan data using hierarchical XGBoost models, with intelligent arsenal correction and an interactive interface for manual data cleaning. The system achieves 93.6% accuracy through 5-fold cross-validation while providing analysts with complete control over the final dataset through visual verification and manually pitch tag editing capabilities.
Built to solve the real-world problem of cleaning large amounts of Trackman data for the purpose of scouting reports and machine learning model training.
Key Features
Hierarchical Classification
Five-model XGBoost architecture with specialized classifiers for different pitch type groups, achieving 93.6% accuracy through 5-fold cross-validation on Big10 conference data.
Intelligent Arsenal Correction
Similarity-based centroid comparison merges pitch types with nearly identical movement profiles (within 4 mph, 4" IVB/HB, 400 RPM), further cleaning the data based on arsenal-specific context.
4D Outlier Detection
Mahalanobis distance-based flagging using velocity, vertical break, horizontal break, and spin rate. Logic only flags pitches closer to other clusters, reducing false positives.
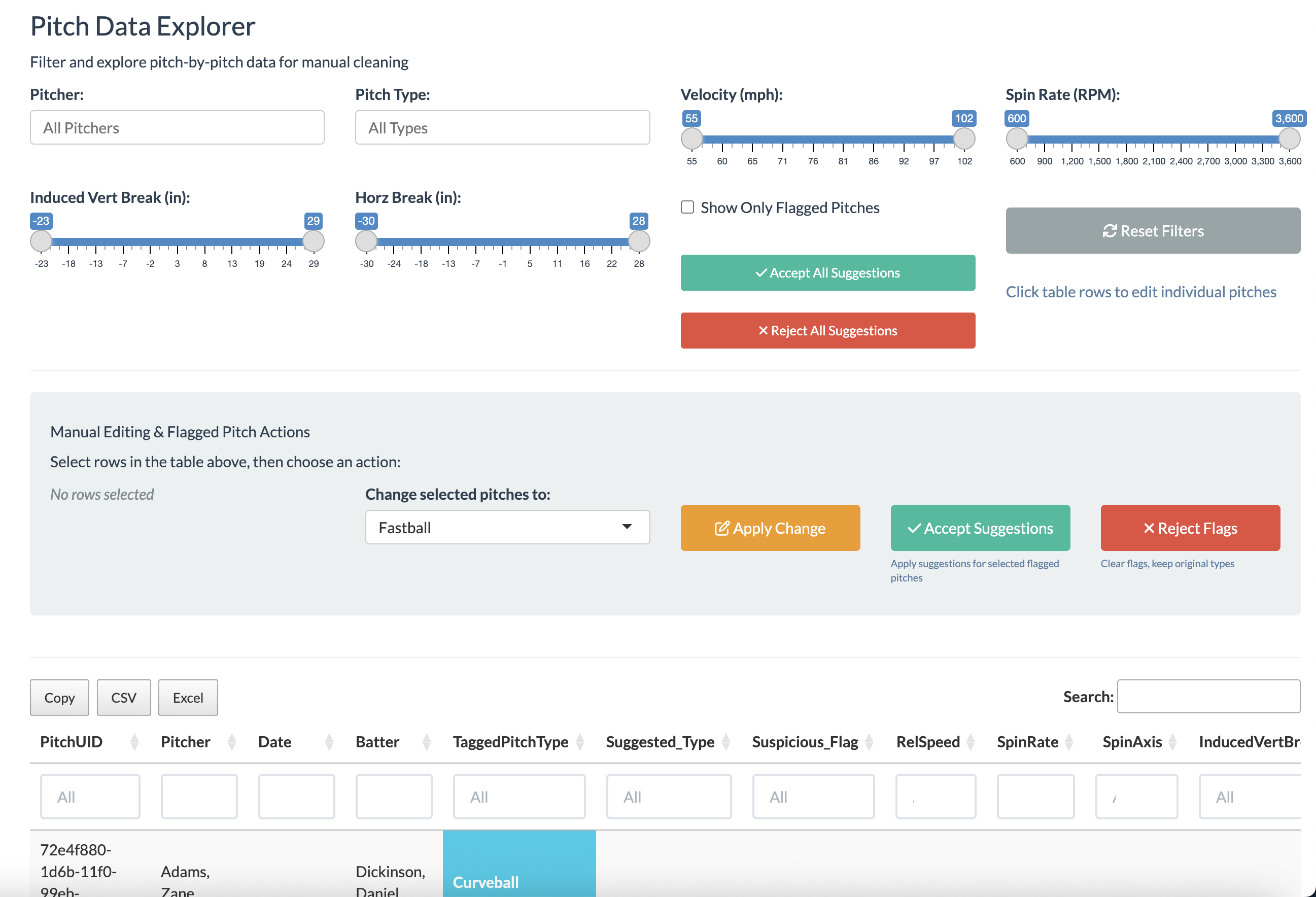
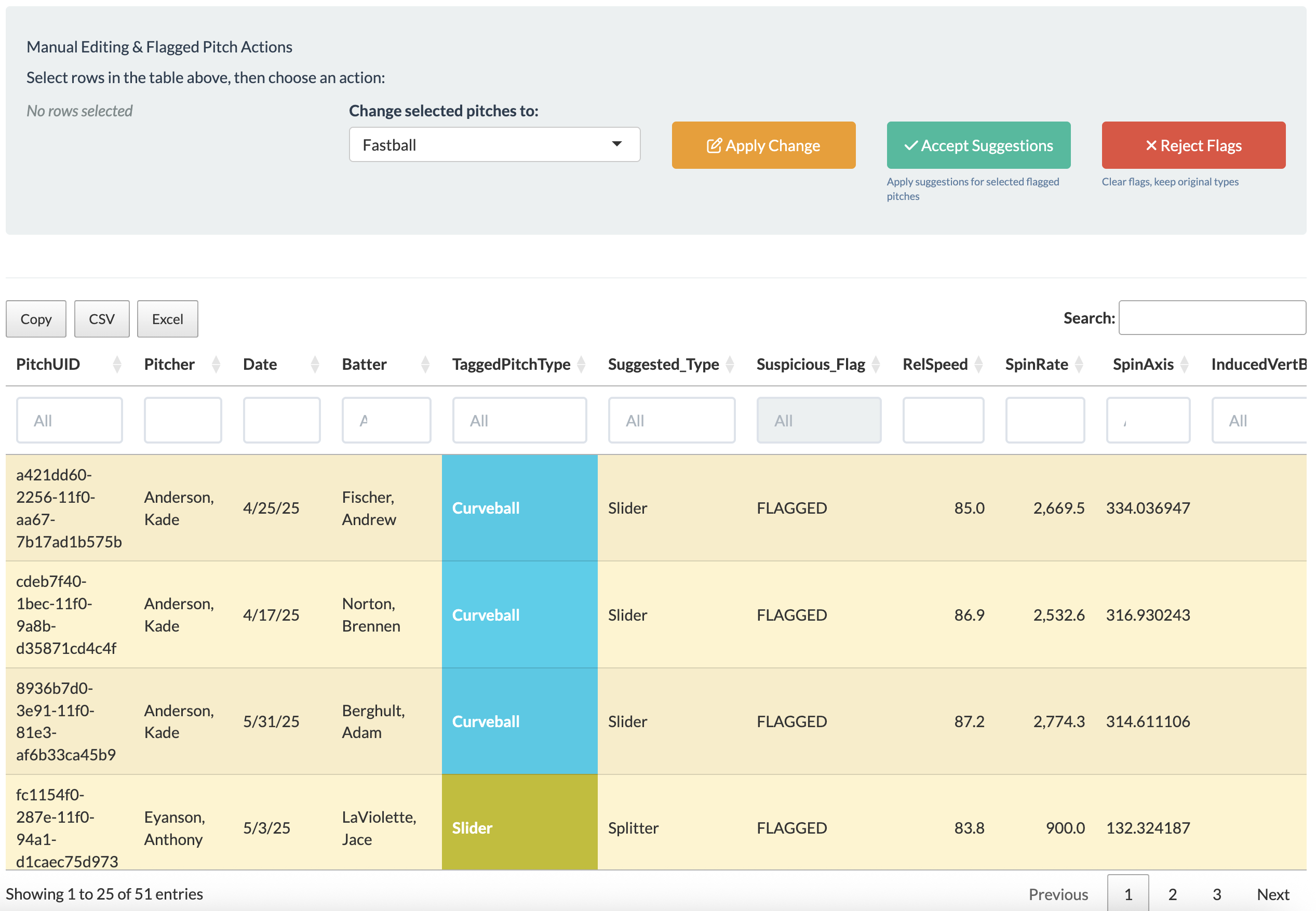
Interactive Data Explorer
Complete filtering interface with multi-select capabilities, range sliders, and "Show Only Flagged" mode. Export to CSV/Excel with one click.
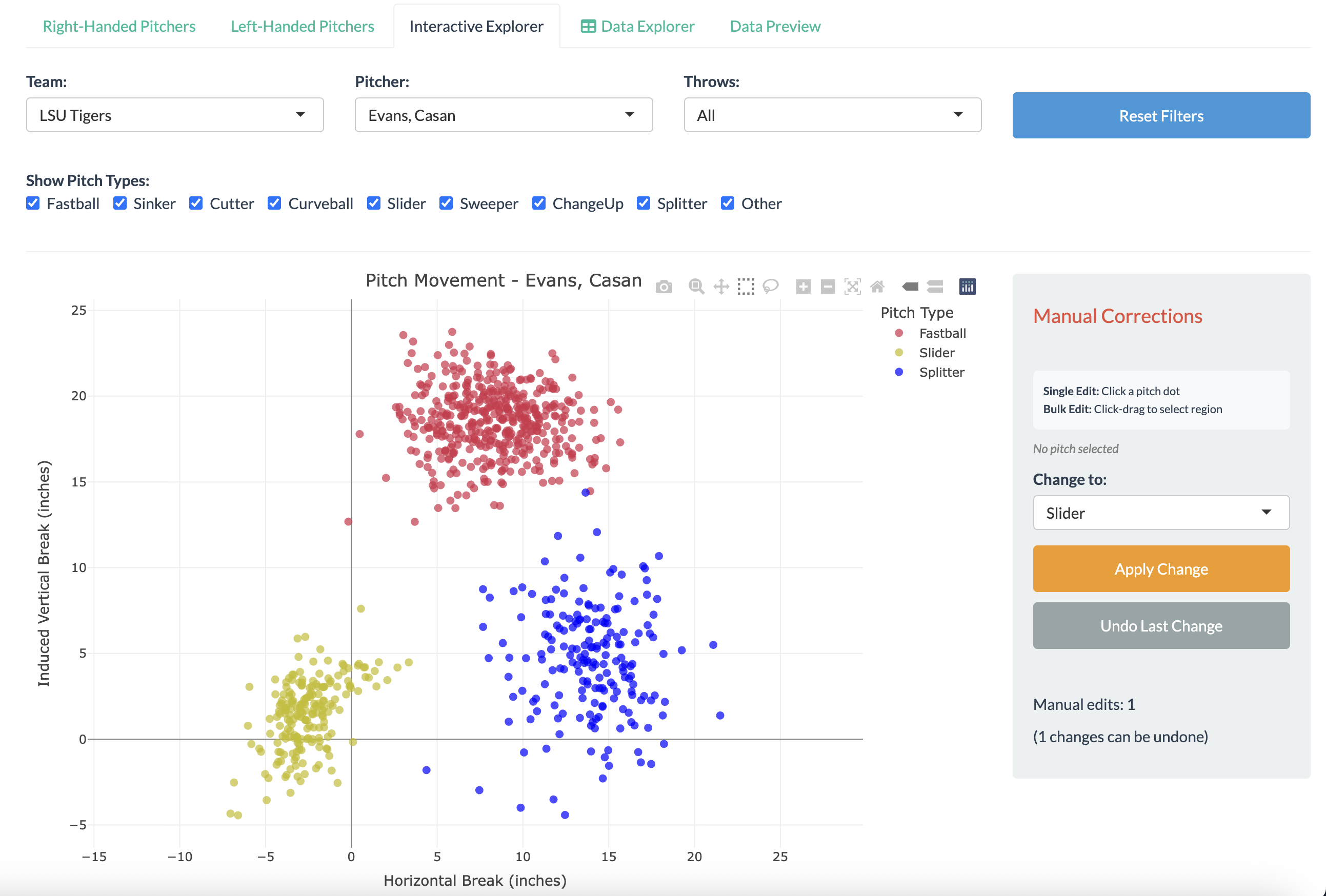
Pitcher Movement Plot Explorer
Interactive Plotly movement charts with click-and-drag selection, team-specific and pitcher-specific filtering, and instant navigation from flagged pitches to visual context. Allows for easy manual data cleaning directly on the movement plot.
Flexible Editing Workflow
Full manual editing of both flagged and regular pitches in the data explorer and on movement plots. Ability to undo changes (50-change history).
🔧 Technical Implementation
Machine Learning Architecture
The classification system uses a hierarchical approach with five XGBoost models:
- Model 1: FastSink vs OffSpeed vs Breaking (three-way pitch group classification)
- Model 2: Fastball vs Sinker (within fastball group)
- Model 3: ChangeUp vs Splitter (within offspeed group, rare pitch boosting)
- Model 4: Curveball vs Cutter vs HorizontalBreaker (within breaking ball group)
- Model 5: Slider vs Sweeper (splits HorizontalBreaker category, specialized features)
Additionally, an optional arsenal correction system may be implemented. Next, a 4D Mahalanobis distance-based flagging system identifies potentially mislabeled pitches after classification. Rare pitch types (Splitter, Cutter, Sweeper) receive boosted class weights during training to address class imbalance.
Feature Engineering
68 engineered features including movement characteristics (IVB, HB, spin), velocity profiles, pitcher-relative metrics (Z-scores, velocity ratios), release point characteristics, and spatial clustering indicators. Movement features weighted more heavily than velocity for better pitch type discrimination.
Arsenal Correction (4D Similarity-Based)
For each pitcher with 30+ pitches, the system:
- Calculates 4D centroids for each pitch type (mean velocity, IVB, HB, spin rate)
- Compares all pairs of pitch types within pitcher's arsenal using Euclidean distance
- Flags pairs as "too similar" if ALL four differences are below thresholds (4 mph, 4", 4", 400 RPM)
- Merges the less common type into the more common type
- Reduces arsenals with too many pitch types to a realistic arsenal (~1% of pitches affected)
Outlier Detection & Flagging
Conservative 4D Mahalanobis distance approach:
- Calculate distance from pitch to its labeled type's cluster centroid (4D space: velo, IVB, HB, spin)
- Flag if distance > 3.7 standard deviations (chi-squared 99.9% threshold for 4 DOF)
- Only keep flag if pitch is closer to a different pitch type's cluster (prevents aggressive flagging)
- Conservative logic designed to minimize false positives while identifying clear outliers
- Result: ~0.5-1% flagging rate on typical datasets
Note on spin rate: While spin is included in the 4D detection, Trackman spin measurements can occasionally be noisy and include misreads. The system's conservative "closer to another cluster" requirement helps filter out spin-driven false positives where movement and velocity profiles are normal.
Application Demonstration
Watch the Pitch Type Classifier in action, showcasing the complete workflow from data upload to final export:
(Coming soon!): Demo video showing data upload, classification, flagging review, and manual editing workflow
Features Showcase
Key interface components and functionality:
📊 Complete Workflow
- Upload TrackMan CSV: System automatically loads and processes data (max 100 MB)
- Classification: Hierarchical XGBoost models classify all pitches (< 10 seconds)
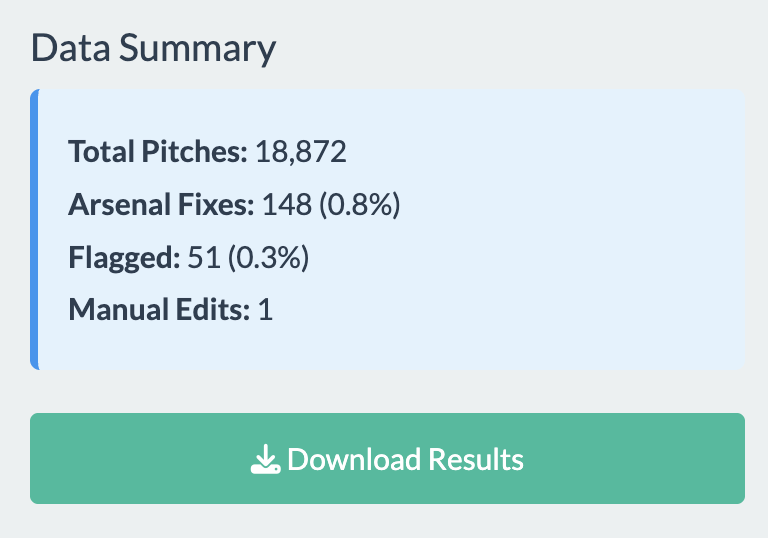
- Arsenal Correction: Centroid-based similarity merging reduces inflated arsenals (~1% of pitches)
- Outlier Flagging: 4D Mahalanobis detection flags suspicious pitches (~0.7% of pitches)
- Interactive Review: Data Explorer shows all flagged pitches with suggestions
- Visual Verification: Click "View in Pitcher Explorer" to see pitch in movement plot context
- Batch or Individual Editing: Accept/Reject all or selected flagged pitches, or manual edit in the data explorer or directly in the movement plot
- Download Clean Data: Export final classified dataset with all corrections applied
Key Innovations
Conservative Flagging Logic
Unlike aggressive outlier detection that flags everything outside normal ranges, this system only flags pitches that are BOTH outliers AND closer to a different pitch type's cluster. This reduces false positives while maintaining high recall for true mislabels.
4D Arsenal Correction
Automatically corrects pitcher arsenals to reduce redunant model predictions (such as a pitcher that was predicted to have both a slider and cutter that are identical).
Integrated Visual Workflow
Rather than forcing users to choose between automated classification and manual editing, the system seamlessly integrates both. Analysts can trust the algorithm for obvious cases, verify uncertain ones visually, and override when domain knowledge suggests otherwise.
📈 Performance & Validation
Training Approach: 5-fold cross-validation on Big 10 conference data (18,872 pitches)
Learning & Development
Key insights from the iterative development process:
- Pitcher-Aware Corrections: The same velocity can represent different pitch types for different pitchers (87 mph could be a changeup for one pitcher, fastball for another), requiring pitcher-specific context.
- Stability Over Complexity: Advanced clustering methods like DBSCAN introduced instability and sometimes collapsed entire arsenals. Simpler similarity-based centroid comparison proved more reliable.
- Domain Expert Integration: Pure algorithmic approaches often violated baseball logic. Allowing manual review and override was essential for production-ready results.
- Spin Rate Considerations: While spin provides valuable information, TrackMan spin measurements can occasionally be noisy. The 4D flagging system's conservative "closer to another cluster" requirement helps filter spin-driven false positives.
Future Enhancements
- Validate and tune spin rate threshold in flagging system using clean reference data
- Add confidence scores to classifications for better uncertainty quantification
- Implement active learning to improve model with user corrections